Adding a Human Touch to Machine Translations
ProductOur team at Curiosity Media had decided to write its own Spanish-English dictionary from scratch, and we used data on what users searched to drive content creation. Insights from user interviews and this search data showed that our results for long-tail search terms, those one-in-ten-thousand long phrases that users typed into our search box, were causing our users frustration.
When we had no data on a query, we sent it to an outside company that would provide a machine-generated translation that we displayed. A previous product manager had contracted three of these services to provide machine translations for long-tail search terms.
The Problem With Machine Translations
However, our newest product manager had made user interviews a more regular part of his work. As the most product-oriented engineer and a fluent Spanish speaker, I filled in to conduct interviews with Spanish speaking users. In these interviews, we noticed that when users interacted with our machine translation page, their confidence in the translations were lower than we expected. In general, they liked seeing the translations, but having three slightly different versions of an answer was confusing.
Since I had worked on processing user search data to drive content creation, the product manager asked me to look into the search data on long-tail search terms to assess the scope of the issue. I found that these kinds of search terms weren’t individually popular enough to merit the content team’s attention over those that were searched thousands of times a month. However, there were enough long-tail search terms that we couldn’t ignore them as a category. By having unsatisfactory results for long searches, we were missing an opportunity to solidify our place as the source for Spanish-English definitions and translations.
We wanted to give our users better results, but we knew that as a company with twelve engineers supporting three products, we weren’t equipped to compete against machine translation services by Microsoft and the like. In fact, trying to do so would go against the direction we’d been taking the company in: distinguishing ourselves from the competition by providing expert, human-created content supported by the latest technology. We’d found a weak point in our strategy. Our human experts couldn’t feasibly cover every phrase that millions of users searched. So, how could we make users more confident that they had the right translation?
Making Machine Translations More Human
We leveraged what we had. And what we had was a team of expert lexicographers working on our project to write our own dictionary.
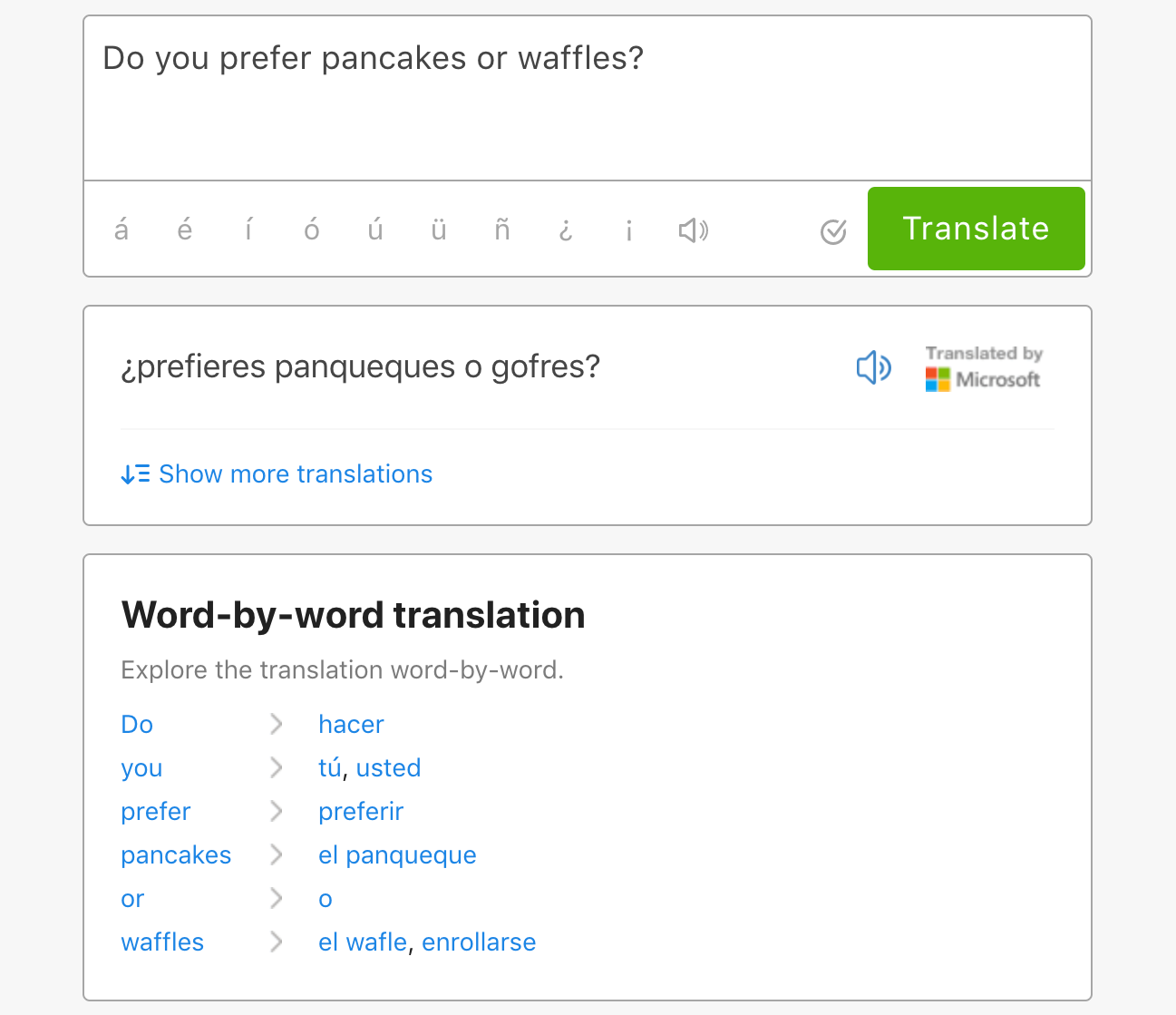
First, we decided to minimize the confusion of showing multiple machine translations by highlighting the best machine translator. To determine the best one, we created a set of sample phrases and translated them with each service. The team of experts behind our dictionary rated the results, and Microsoft emerged as the winner.
We changed our default view to show only Microsoft’s translation. We would reveal the other two translations only if a user clicked “Show more translations.” For this update, we added click tracking to confirm that only a small fraction of users wanted to see additional translations. If too many users clicked to see all three, we could reverse the change.
Next, we brought the content team, product manager, graphic designer, and engineers together to brainstorm ways we could better support users puzzling through machine translations of long phrases. We noted that while we didn’t have expert, human translations for long phrases, we did have expert, human translations for all the words that made up the long phrases. The idea for a word-by-word translation feature was born.
Our designer created mock ups for a new block that showed the top “header” translation for each word in a phrase, and our product manager conducted user interviews to get feedback on the concept. I sketched out the logic we would use to pull the translations from the dictionary data and showed samples to the content team to get their input. I also worked with the other engineers to plan the architecture of a new micro-service endpoint to retrieve the translations.
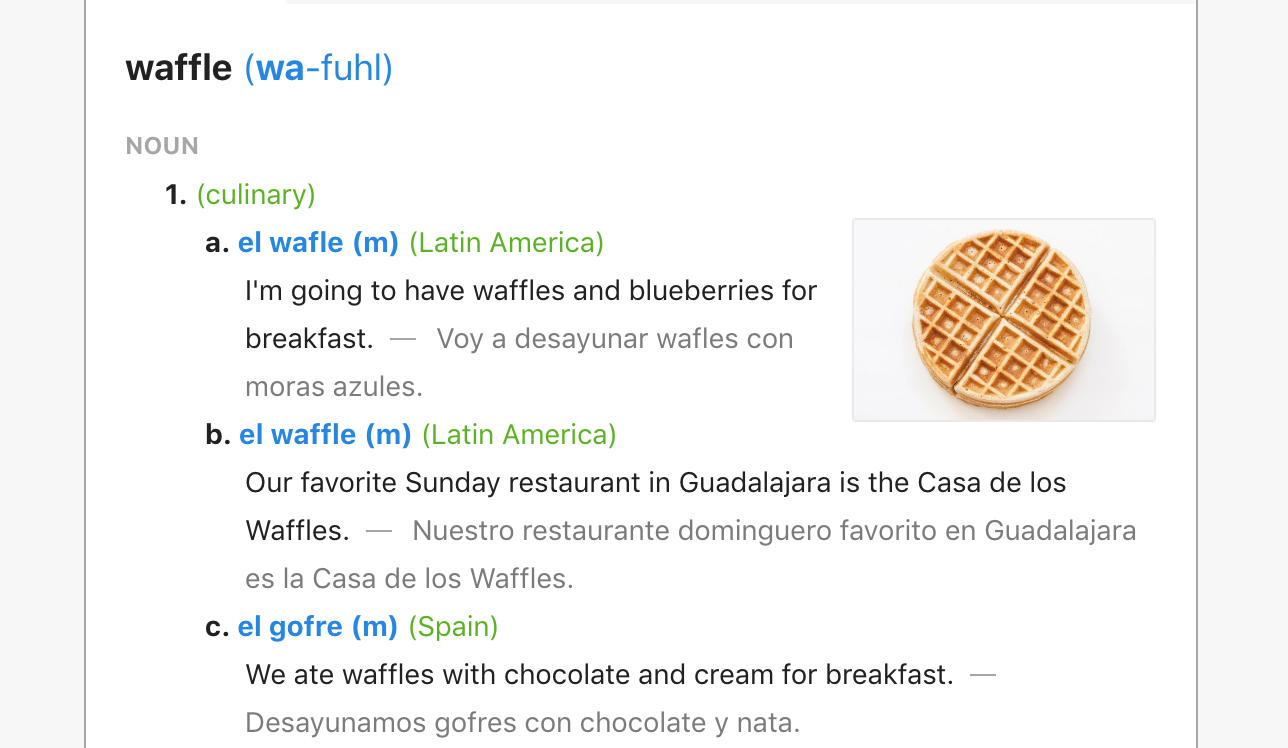
The plans were well received, and we iterated with a few changes. I pushed to link each word back to its full dictionary entry, so that users could reach more detailed information about a specific word in a single click.
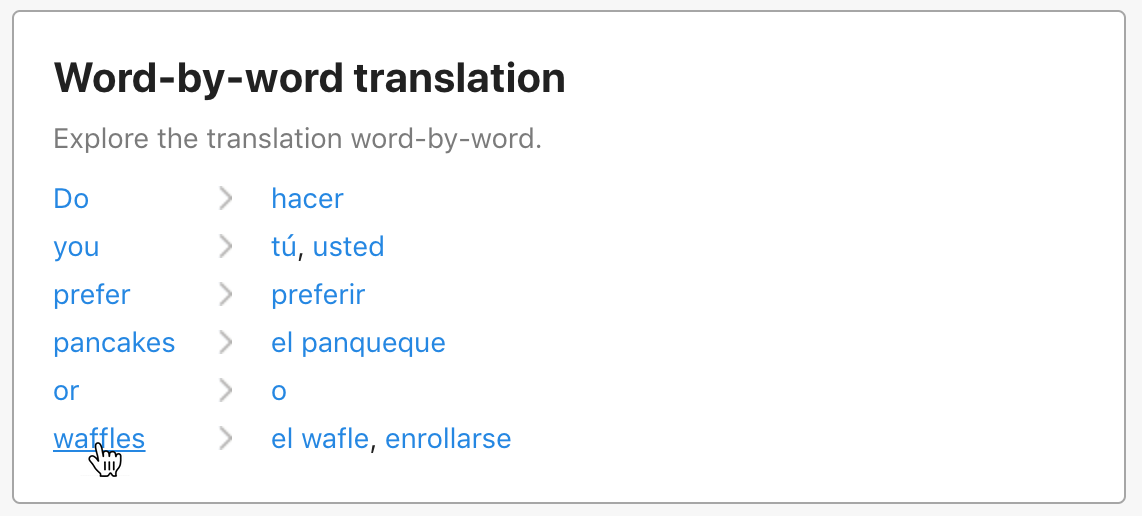
Clicking through to the full entry of any tricky word would give a user confidence that they’re picking the correct word by supplying information about which translations are used in different regions of the world or including example sentences for additional context. This change would also reduce friction for users to extend their session into visiting multiple pages.
After incorporating this and a few other tweaks, we had consensus and got to work. A teammate and I built the new service and implemented the UX designs. We coordinated with the content team to launch the new feature and closely tracked users’ early feedback.
Results
Now, when a user tries to translate a rare or long phrase that’s not in our dictionary, they’re able to see a suggested machine translation, word-by-word translations, and an easy path to in-depth information. Our updates boosted our users’ confidence in our answers to their longest questions.
We used both qualitative data from user interviews and quantitative data from user search terms to zoom out and identify a category of search terms that we weren’t addressing effectively. More importantly, we gathered a multi-disciplinary team of stakeholders to brainstorm ways to improve our results. By collaborating across departments, we were able to direct our engineering team on how to leverage our expert, human-created content and better answer the questions of our users.